Museum für Naturkunde Berlin
AllemagneLe défi
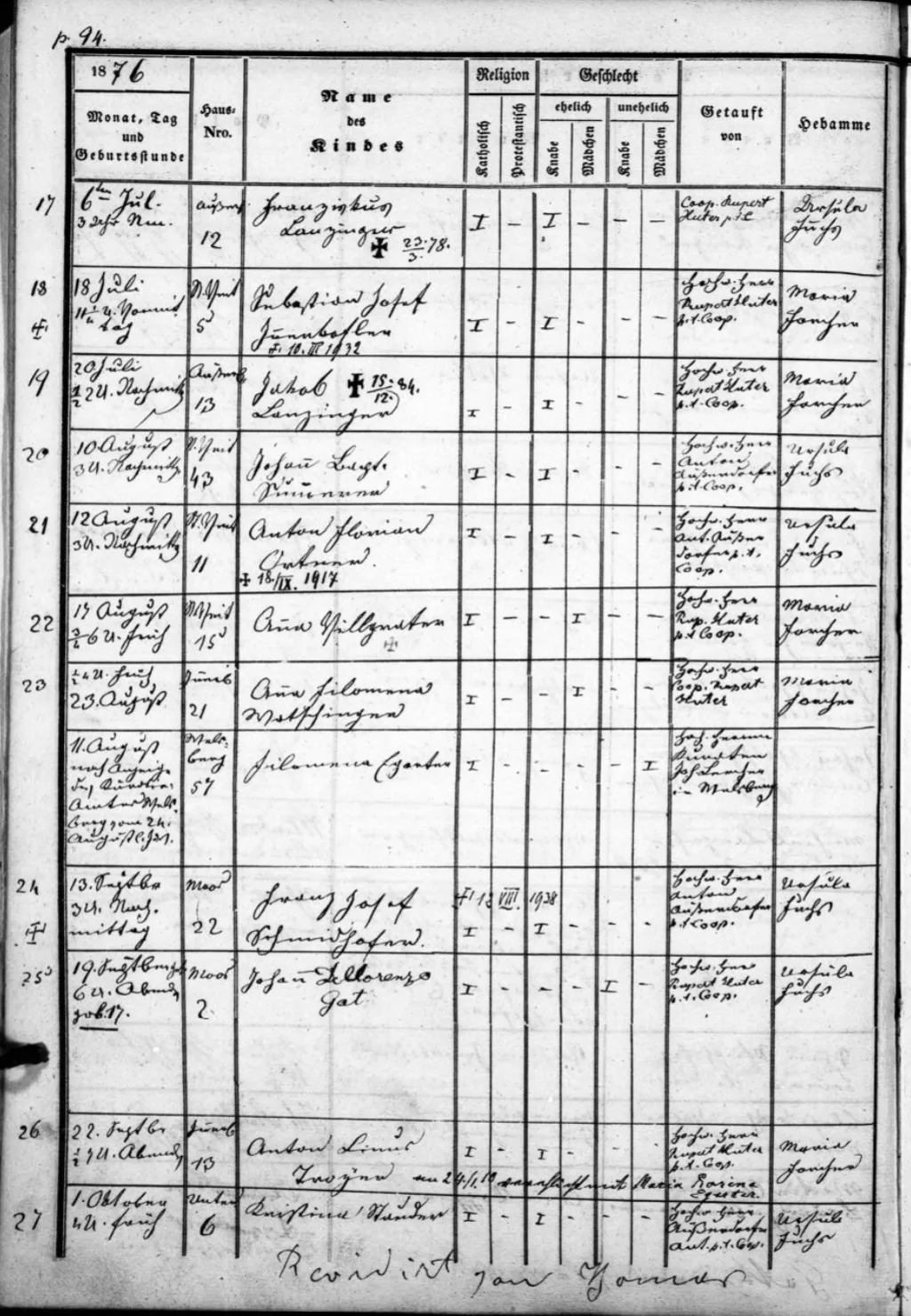
250 000 étiquettes de spécimens avec des métadonnées manuscrites couvrant deux siècles. L'OCR standard a complètement échoué — encre pâlie, papier endommagé, écritures mixtes et mises en page non standard.
Notre approche
Développement d'un modèle Smart Extract — une IA qui comprend contextuellement la structure des étiquettes. Ajout de la reconnaissance d'entités nommées avec enrichissement GeoNames pour le balisage automatique des espèces et la résolution des noms de lieux.
Le résultat
Premier déploiement réel réussi d'un modèle Smart Extract. Jeu de données complet de 250 000 étiquettes transcrites et balisées — un modèle reproductible pour les collections d'histoire naturelle du monde entier.