Zet historische tabellen om in gestructureerde data
Transkribus Table Models gebruiken instance segmentation om rijen en kolommen in documentafbeeldingen te detecteren en tabelgegevens met ongeëvenaarde nauwkeurigheid naar spreadsheets te exporteren.
Begin met het trainen van uw model
Bekijk de extractie in actie
Table Models detecteren de rasterstructuur van uw document en extraheren de inhoud van elke cel naar een gestructureerde spreadsheet die u kunt exporteren.
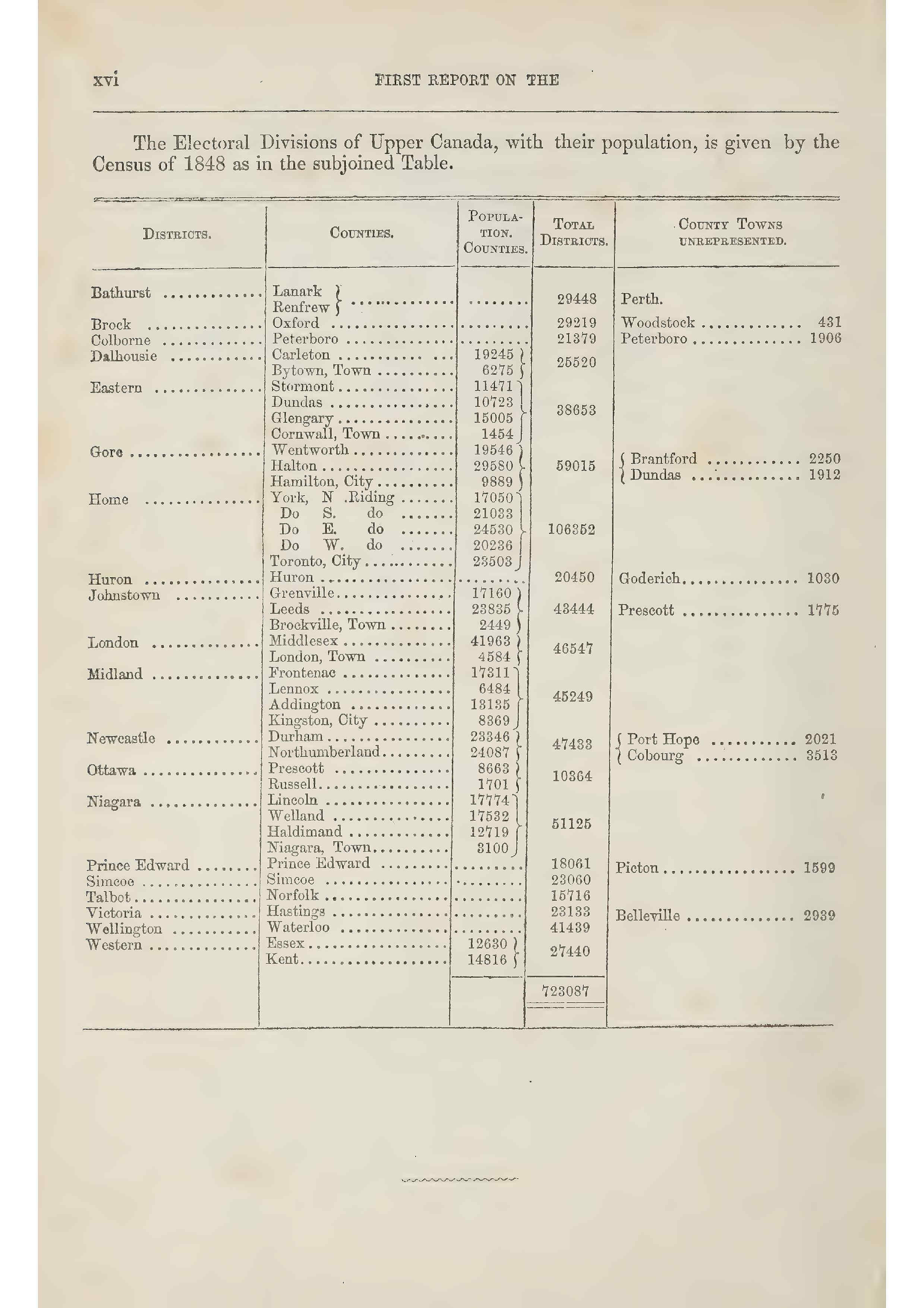
| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914, 5/18/16 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914, 8/7/16 |
| Fessenden Acad. & Ind. School | Fessenden, Fla. | General | 12/22/16 | ||
| Florida Baptist Academy (2) | Jacksonville, Fla. | General | 4/27/17 | ||
| Fort Valley High & Ind. School | Fort Valley, Ga. | 12,500 | Building | 12/15/17 | |
| Fisk University | Nashville, Tenn. | 50,000 | General | 12/5/18 | |
| First Dist. State Normal School | Kirksville, Mo. | Library Building | 2/26/19 | Gen. 3/3/19 |
Gebouwd voor elk type tabelvormig document
Van ledenregisters tot volkstellingsgegevens: Table Models verwerken het volledige spectrum van historische tabellen met consistente nauwkeurigheid.
Ledenregisters & grootboeken
Handgeschreven ledenlijsten, verenigingsregisters en financiële grootboeken met duidelijk gedefinieerde kolommen. Table Models blinken uit bij deze uniforme rasterstructuren en detecteren rijen en kolommen nauwkeurig, zelfs wanneer het handschrift sterk varieert tussen de vermeldingen.

Volkstellings- & statistische tabellen
Gedrukte volkstellingsformulieren, bevolkingsenquêtes en statistische tabellen met complexe kopteksten. Zelfs voorgedrukte formulieren met fijne rasterlijnen worden betrouwbaar verwerkt, waardoor pagina's met demografische gegevens worden omgezet in bruikbare spreadsheets voor grootschalige analyse.
Meerregelige vermeldingen & scheve rijen
Aanvraagregisters en uitgebreide records waarbij cellen meerdere regels tekst bevatten. Table Models verwerken meerregelige inhoud binnen cellen op natuurlijke wijze, en zelfs scheve of geroteerde rijscheidingen worden correct gedetecteerd dankzij instance segmentation.

Administratieve & institutionele tabellen
Onderwijsregisters, financiële overzichten en administratieve tabellen met vele kolommen handgeschreven gegevens. Of uw tabel nu 3 kolommen heeft of 30, Table Models schalen mee en herkennen de structuur nauwkeurig over honderden pagina's.
Gestructureerde output, klaar voor gebruik
Elke gedetecteerde cel wordt gekoppeld aan zijn rij- en kolompositie, wat u schone gestructureerde data oplevert die u direct kunt exporteren.
<TableRegion id="t1">
<Coords points="0,646 0,4014 6060,4013 6060,638"/>
<TableCell row="0" col="0">
<Coords points="0,646 0,822 1548,822 1548,644"/>
<TextLine>
<Unicode>Franklin College (6)</Unicode>
</TextLine>
</TableCell>
<TableCell row="0" col="1">
<Coords points="1548,644 1548,822 2241,822 2241,644"/>
<TextLine>
<Unicode>New Athen, O.</Unicode>
</TextLine>
</TableCell>
<!-- ... -->
</TableRegion>| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914 |
| Fessenden Acad. | Fessenden, Fla. | General | 12/22/16 |
Exporteer uw tabellen in meerdere formaten
Hoe Table Models werken
Een drietraps-pipeline transformeert uw documentafbeeldingen naar gestructureerde tabeldata.
Tabelstructuurherkenning
Twee instance-segmentatiemodellen draaien parallel: het ene detecteert horizontale rijscheidingen, het andere detecteert verticale kolomscheidingen. De resultaten worden samengevoegd tot een complete rasterstructuur.
Tekstlijndetectie
Binnen elke gedetecteerde cel worden tekstbasislijnen geïdentificeerd. Deze stap verwerkt meerregelige cellen op natuurlijke wijze en detecteert elke tekstregel ongeacht de celhoogte.
Tekstherkenning
Een HTR-model leest de gedetecteerde tekstregels en produceert de uiteindelijke transcriptie. Het resultaat is een gestructureerde spreadsheet waarin elke waarde is gekoppeld aan zijn rij en kolom.
| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914 |
Hoe train je een Table Model
Table Models zijn niet kant-en-klaar — je traint ze op je specifieke documenten. Zo werkt het.
Tabellen annoteren
Open je documenten in Transkribus en teken de rij- en kolomstructuur op elke pagina. Markeer elke rij- en kolomscheiding zodat het model je specifieke tabelindeling kan leren.
Trainen
Zodra je ongeveer 20 pagina's hebt geannoteerd (meer voor complexe layouts), dien je ze in om je eigen Table Model te trainen. Het trainen duurt doorgaans enkele uren.
Toepassen & itereren
Pas je getrainde model toe op nieuwe documenten — het detecteert automatisch tabelstructuren en extraheert celinhoud. Gebruik de resultaten om fouten te corrigeren, meer pagina's toe te voegen en opnieuw te trainen.
Train uw eigen Table Model
Begin met slechts 20 geannoteerde pagina's en verbeter de nauwkeurigheid van uw model stap voor stap.
Voor eenvoudige, uniforme tabellen zijn 20 geannoteerde pagina's voldoende om een eerste werkend model te trainen.
Een Mean Average Precision van 35% of hoger levert in de praktijk al betrouwbare tabeldetectie op.
Tips van de experts
- Begin met eenvoudige, uniforme tabellen en breid later uit naar complexere lay-outs
- Sluit koptekstrijen uit tijdens de eerste training om de structuur consistent te houden
- Gebruik 50–100 pagina's voor complexe of gemengde tabellay-outs
- Itereer: train, evalueer, corrigeer fouten, hertrain voor de beste resultaten
- Table Models werken het best voor strikte rasterstructuren — gebruik voor formulieren en onregelmatige lay-outs in plaats daarvan Field Models
Table Models vs. Field Models
Kies het juiste hulpmiddel voor uw documentstructuur.
Tabelmodellen
Het beste voor uniforme rasterstructuren waarbij data in consistente rijen en kolommen is georganiseerd.
- Rijen × kolommen rasterdetectie
- Meerregelige tekst per cel
- Scheve rijen en kolommen worden ondersteund
- Exporteren als XLSX, CSV, PAGE XML
- Ideaal voor: registers, grootboeken, volkstellingstabellen
Veldmodellen
Het beste voor complexe lay-outs, formulieren en documenten waarbij gebieden onregelmatige vormen hebben.
- Getagde gebieden van elke vorm
- Onregelmatige en overlappende gebieden
- Aangepaste veldtypen en labels
- Werkt voor elke documentstructuur
- Ideaal voor: formulieren, brieven, indexkaarten
Begin vandaag nog met het extraheren van tabeldata
Train een aangepast Table Model op uw documenten en ontsluit gestructureerde data uit duizenden handgeschreven tabellen.