Historische Tabellen in strukturierte Daten verwandeln
Transkribus Tabellenmodelle nutzen Instanzsegmentierung, um Zeilen und Spalten in Dokumentenbildern zu erkennen und tabellarische Daten mit unerreichter Genauigkeit in Tabellenkalkulationen zu extrahieren.
Eigenes Modell trainieren
Sehen Sie die Extraktion in Aktion
Tabellenmodelle erkennen die Rasterstruktur Ihres Dokuments und extrahieren den Inhalt jeder Zelle in eine strukturierte Tabellenkalkulation, die Sie exportieren können.
| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914, 5/18/16 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914, 8/7/16 |
| Fessenden Acad. & Ind. School | Fessenden, Fla. | General | 12/22/16 | ||
| Florida Baptist Academy (2) | Jacksonville, Fla. | General | 4/27/17 | ||
| Fort Valley High & Ind. School | Fort Valley, Ga. | 12,500 | Building | 12/15/17 | |
| Fisk University | Nashville, Tenn. | 50,000 | General | 12/5/18 | |
| First Dist. State Normal School | Kirksville, Mo. | Library Building | 2/26/19 | Gen. 3/3/19 |
Für jede Art von tabellarischem Dokument entwickelt
Von Mitgliederlisten bis zu Volkszählungsunterlagen – Tabellenmodelle verarbeiten das gesamte Spektrum historischer Tabellen mit gleichbleibender Genauigkeit.
Mitgliederverzeichnisse & Kassenbücher
Handschriftliche Mitgliederlisten, Vereinsregister und Finanzbücher mit klar definierten Spalten. Tabellenmodelle sind besonders stark bei diesen gleichmäßigen Rasterstrukturen und erkennen Zeilen und Spalten präzise, selbst wenn die Handschrift zwischen den Einträgen stark variiert.

Volkszählungs- & Statistiktabellen
Gedruckte Volkszählungsformulare, Bevölkerungserhebungen und statistische Tabellen mit komplexen Kopfzeilen. Selbst vorgedruckte Formulare mit feinen Rasterlinien werden zuverlässig verarbeitet und verwandeln Seiten voller demografischer Daten in nutzbare Tabellenkalkulationen für großangelegte Analysen.
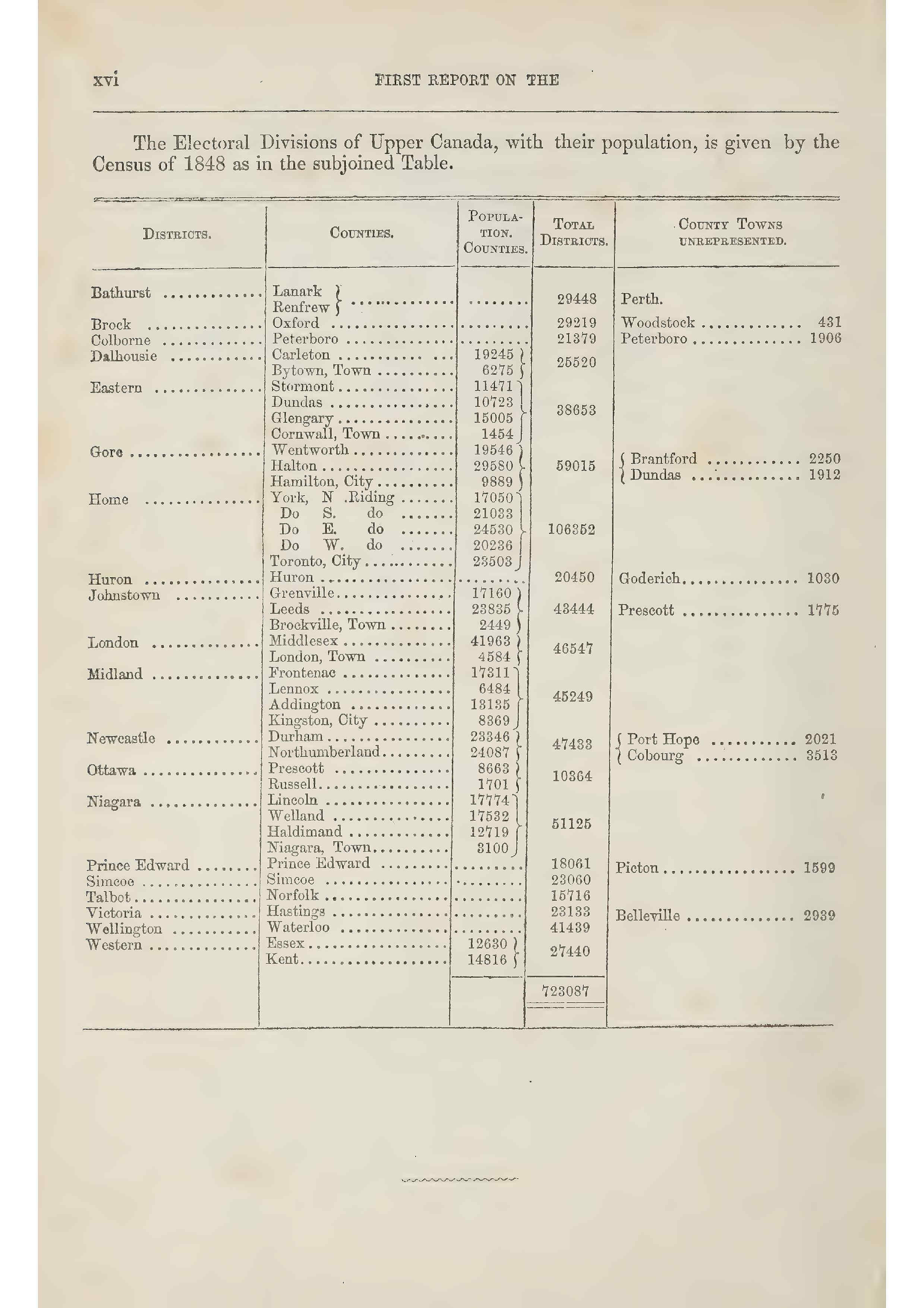
Mehrzeilige Einträge & schiefe Zeilen
Antragsregister und ausführliche Aufzeichnungen, bei denen Zellen mehrere Textzeilen enthalten. Tabellenmodelle verarbeiten mehrzeilige Inhalte innerhalb von Zellen mühelos, und selbst schiefe oder gedrehte Zeilentrennlinien werden dank Instanzsegmentierung korrekt erkannt.

Verwaltungs- & Institutionstabellen
Schulunterlagen, Finanzberichte und Verwaltungstabellen mit vielen Spalten handschriftlicher Daten. Ob Ihre Tabelle 3 oder 30 Spalten hat – Tabellenmodelle erkennen die Struktur zuverlässig über Hunderte von Seiten hinweg.
Strukturierte Ausgabe, sofort einsatzbereit
Jede erkannte Zelle wird ihrer Zeilen- und Spaltenposition zugeordnet, sodass Sie saubere, strukturierte Daten erhalten, die Sie direkt exportieren können.
<TableRegion id="t1">
<Coords points="0,646 0,4014 6060,4013 6060,638"/>
<TableCell row="0" col="0">
<Coords points="0,646 0,822 1548,822 1548,644"/>
<TextLine>
<Unicode>Franklin College (6)</Unicode>
</TextLine>
</TableCell>
<TableCell row="0" col="1">
<Coords points="1548,644 1548,822 2241,822 2241,644"/>
<TextLine>
<Unicode>New Athen, O.</Unicode>
</TextLine>
</TableCell>
<!-- ... -->
</TableRegion>| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914 |
| Fessenden Acad. | Fessenden, Fla. | General | 12/22/16 |
Exportieren Sie Ihre Tabellen in verschiedenen Formaten
So funktionieren Tabellenmodelle
Eine dreistufige Pipeline verwandelt Ihre Dokumentenbilder in strukturierte tabellarische Daten.
Tabellenstrukturerkennung
Zwei Instanzsegmentierungsmodelle arbeiten parallel: Eines erkennt horizontale Zeilentrennlinien, das andere vertikale Spaltentrennlinien. Die Ergebnisse werden zu einer vollständigen Rasterstruktur zusammengeführt.
Textzeilenerkennung
Innerhalb jeder erkannten Zelle werden Textgrundlinien identifiziert. Dieser Schritt verarbeitet mehrzeilige Zellen mühelos und erkennt jede Textzeile unabhängig von der Zellhöhe.
Texterkennung
Ein HTR-Modell liest die erkannten Textzeilen und erstellt die endgültige Transkription. Das Ergebnis ist eine strukturierte Tabellenkalkulation, in der jeder Wert seiner Zeile und Spalte zugeordnet ist.
| Institution | Town | Amount | Object | Date | Disposition |
|---|---|---|---|---|---|
| Franklin College (6) | New Athen, O. | General | 3/23/16 | ||
| Fargo College (3) | Fargo, N.D. | 100,000 | Endowment | 4/27/16 | Gen 1914 |
| Franklin Academy (2) | Franklin, Neb. | 5,000 | Library Building | 8/3/16 | Gen 1914 |
So trainieren Sie ein Table Model
Table Models sind keine fertigen Modelle — Sie trainieren sie auf Ihren spezifischen Dokumenten. So sieht der Prozess aus.
Tabellen annotieren
Öffnen Sie Ihre Dokumente in Transkribus und zeichnen Sie die Zeilen- und Spaltenstruktur auf jeder Seite ein. Markieren Sie jeden Zeilen- und Spaltentrenner, damit das Modell Ihr spezifisches Tabellenlayout lernen kann.
Trainieren
Sobald Sie etwa 20 Seiten annotiert haben (mehr bei komplexen Layouts), reichen Sie diese ein, um Ihr eigenes Table Model zu trainieren. Das Training dauert in der Regel einige Stunden.
Anwenden & iterieren
Wenden Sie Ihr trainiertes Modell auf neue Dokumente an — es erkennt automatisch Tabellenstrukturen und extrahiert Zellinhalte. Nutzen Sie die Ergebnisse, um Fehler zu korrigieren, weitere Trainingsseiten hinzuzufügen und für noch bessere Genauigkeit neu zu trainieren.
Trainieren Sie Ihr eigenes Tabellenmodell
Starten Sie mit nur 20 annotierten Seiten und verbessern Sie die Genauigkeit Ihres Modells iterativ.
Für einfache, einheitliche Tabellen reichen 20 annotierte Seiten aus, um ein erstes funktionsfähiges Modell zu trainieren.
Eine Mean Average Precision von 35 % oder höher liefert in der Praxis bereits eine zuverlässige Tabellenerkennung.
Tipps von den Experten
- Beginnen Sie mit einfachen, einheitlichen Tabellen und erweitern Sie später auf komplexere Layouts
- Schließen Sie Kopfzeilen beim ersten Training aus, um die Struktur konsistent zu halten
- Verwenden Sie 50–100 Seiten für komplexe oder gemischte Tabellenlayouts
- Iterieren: trainieren, bewerten, Fehler korrigieren, erneut trainieren für beste Ergebnisse
- Tabellenmodelle eignen sich am besten für strikte Rasterstrukturen – für Formulare und unregelmäßige Layouts verwenden Sie stattdessen Feldmodelle
Tabellenmodelle vs. Feldmodelle
Wählen Sie das richtige Werkzeug für Ihre Dokumentstruktur.
Tabellenmodelle
Ideal für einheitliche Rasterstrukturen, bei denen Daten in konsistenten Zeilen und Spalten organisiert sind.
- Zeilen × Spalten Rastererkennung
- Mehrzeiliger Text pro Zelle
- Schiefe Zeilen und Spalten werden unterstützt
- Export als XLSX, CSV, PAGE XML
- Ideal für: Register, Kassenbücher, Volkszählungstabellen
Feldmodelle
Ideal für komplexe Layouts, Formulare und Dokumente, bei denen Bereiche unregelmäßige Formen haben.
- Markierte Bereiche jeder Form
- Unregelmäßige und überlappende Bereiche
- Benutzerdefinierte Feldtypen und Bezeichnungen
- Funktioniert für jede Dokumentstruktur
- Ideal für: Formulare, Briefe, Karteikarten
Starten Sie noch heute mit der Extraktion tabellarischer Daten
Trainieren Sie ein individuelles Tabellenmodell auf Ihren Dokumenten und erschließen Sie strukturierte Daten aus Tausenden handschriftlicher Tabellen.