Museum für Naturkunde Berlin
DeutschlandDie Herausforderung
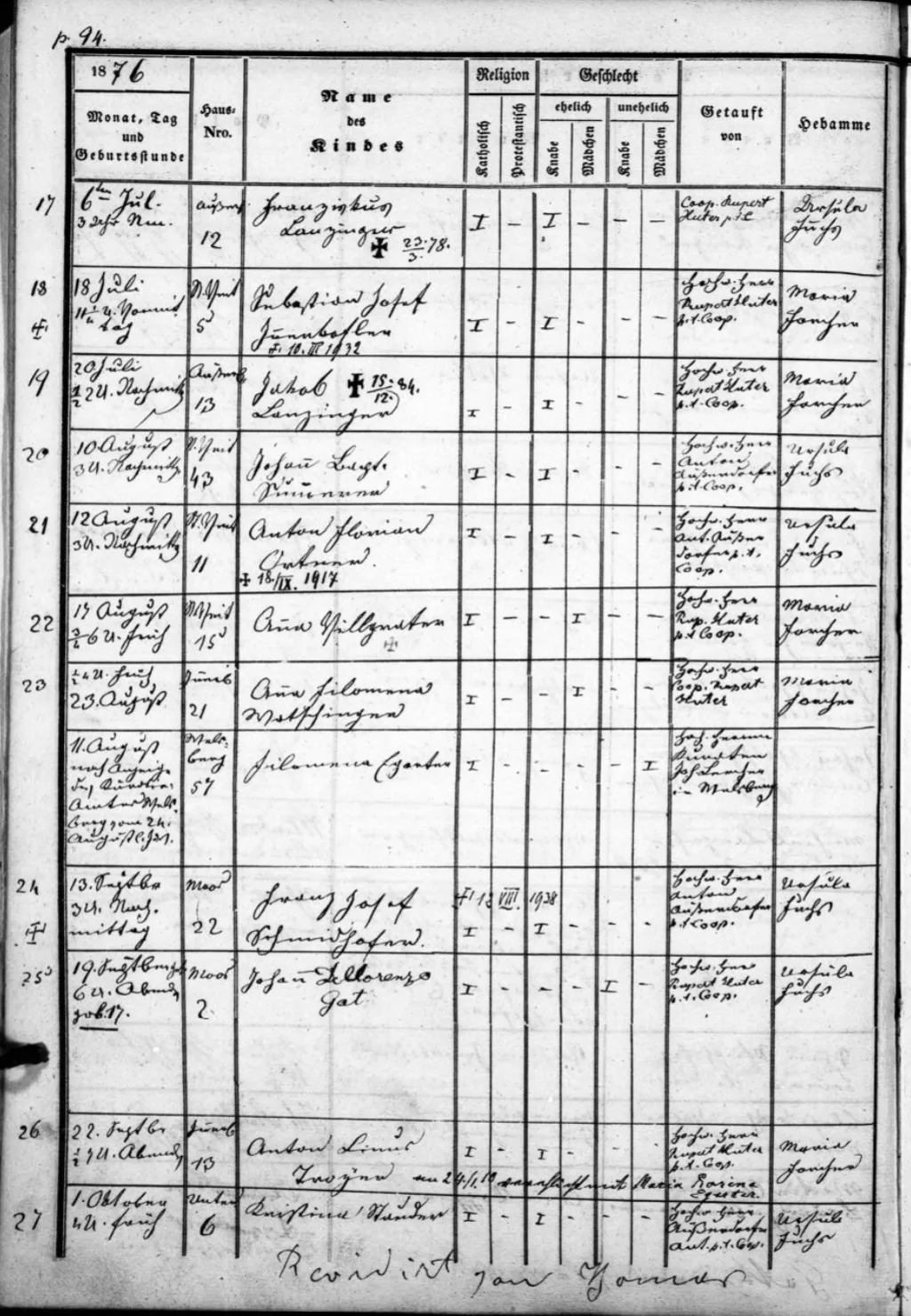
250.000 Etiketten mit handschriftlichen Metadaten aus zwei Jahrhunderten. Standard-OCR versagte komplett — verblasste Tinte, beschädigtes Papier, gemischte Schriften und nicht-standardisierte Layouts.
Unser Ansatz
Entwicklung eines Smart Extract-Modells — eine KI, die Etikettenstrukturen kontextuell versteht. Ergänzt durch Named Entity Recognition mit GeoNames-Anreicherung für automatisches Tagging von Arten und Auflösung von Ortsnamen.
Das Ergebnis
Erster erfolgreicher realer Einsatz eines Smart Extract-Modells. Vollständiger maschinenlesbarer Datensatz von 250.000 transkribierten und getaggten Etiketten — ein replizierbares Modell für Naturkundesammlungen weltweit.