Het probleem
Waarom standaard OCR faalt op handschrift
Optical Character Recognition (OCR) is ontworpen voor gedrukte tekst — uniforme lettertypen met consistente letterafstand en voorspelbare lay-outs. Wanneer toegepast op handgeschreven documenten produceert standaard OCR onbruikbare resultaten. Handschrift is inherent variabel: lettervormen verschillen tussen schrijvers, tekens verbinden op onvoorspelbare manieren, en historische schriften zoals Kurrent, Sütterlin of Secretary Hand lijken nauwelijks op modern drukwerk. Dit is het kernprobleem waarvoor handgeschreven tekstherkenning is ontwikkeld.
Standaard OCR-engines verwachten uniforme tekenvormen — handschrift varieert tussen elke schrijver en zelfs binnen een enkele pagina
Verbonden en cursieve schriften kunnen niet worden gesegmenteerd in individuele tekens zoals gedrukte tekst
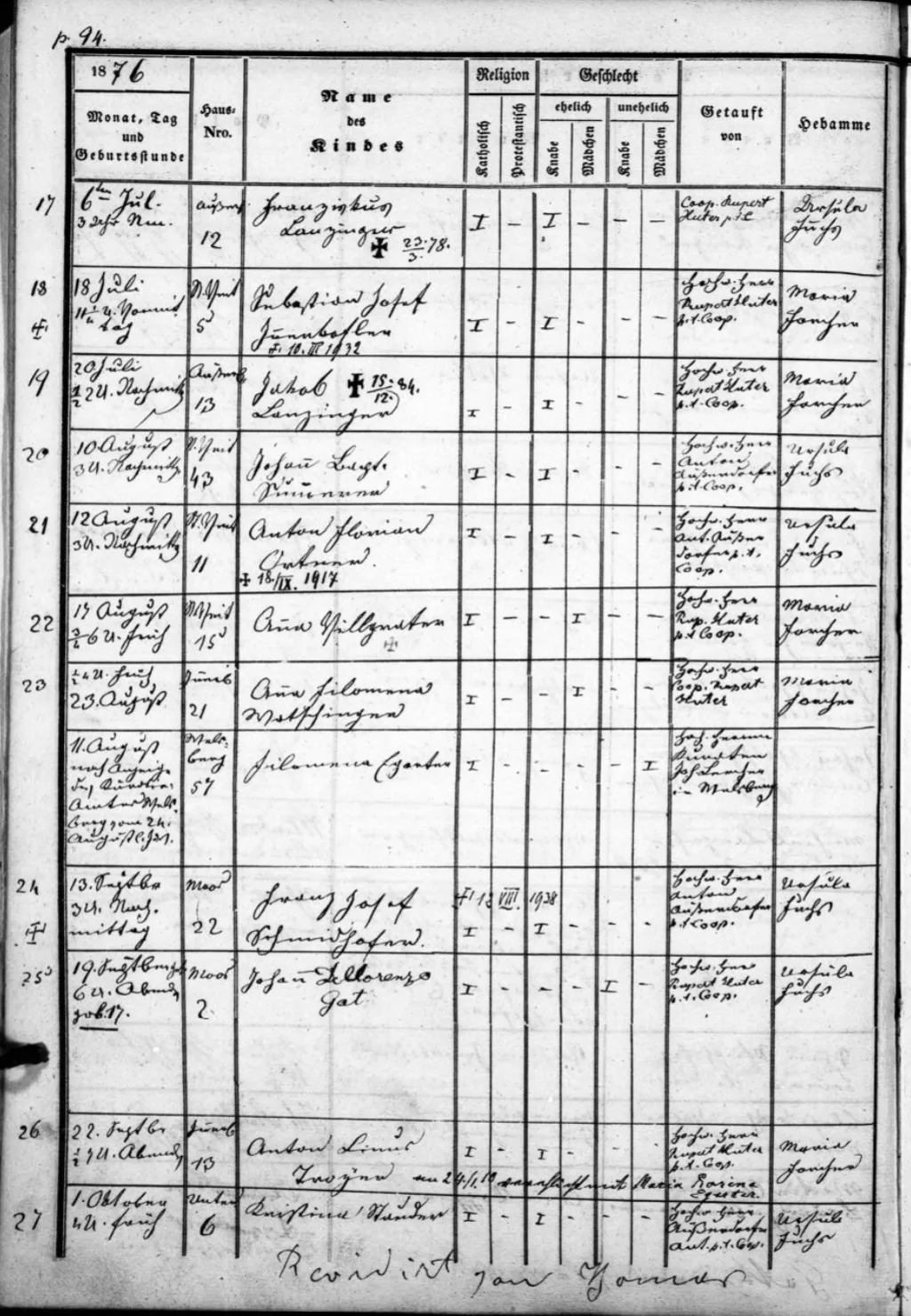
Historische schriften (Kurrent, Secretary Hand, Copperplate) gebruiken lettervormen die ontbreken in moderne OCR-trainingssets
Afkortingen, ligaturen en superscriptconventies in historische manuscripten hebben geen equivalent in drukwerk
Documentdegradatie — vervaagde inkt, doordruk, vosvorming — vergroot de uitdaging voorbij wat regelgebaseerde systemen aankunnen
De oplossing
Hoe werkt HTR? AI-handschriftherkenning uitgelegd
Handgeschreven tekstherkenning maakt gebruik van diepe neurale netwerken — doorgaans een combinatie van convolutionele neurale netwerken (CNN's) en recurrente neurale netwerken (RNN's) — om de visuele patronen van handschrift direct te leren uit gelabelde voorbeelden. In plaats van te vertrouwen op vooraf gedefinieerde regels over hoe letters eruitzien, wordt een HTR-model getraind op duizenden beelden gekoppeld aan hun correcte transcripties (zogenaamde "ground truth"). Door deze training leert het model niet alleen individuele tekens te herkennen, maar ook sequenties van verbonden streken, contextuele lettervormen en de ruimtelijke relaties tussen tekstelementen op een pagina.
Lay-outanalyse detecteert tekstgebieden, regels en structurele elementen (kolommen, tabellen, marginalia) op de pagina
Regelsegmentatie isoleert individuele tekstregels uit de gedetecteerde lay-out
Het neurale netwerk verwerkt elk regelbeeld en voorspelt een sequentie van tekens, rekening houdend met context van omliggende streken
Taalmodellering en naverwerking verfijnen de output, waarbij ambigue tekens worden opgelost met behulp van statistische patronen
Betrouwbaarheidsscores worden toegekend aan elk voorspeld teken en elke regel, wat gerichte kwaliteitscontrole mogelijk maakt

Addres to dear Isabella on the Authors
recovery
O Isa pain did visit me
I was at the last extremity
How often did I think of you
I wished your graceful form to view
To clasp you in my weak embrace
Indeed I thought Id run my race
Good Care Im sure was of me taken
But indeed I was much shaken
At last I daily strength did gain
HTR vs OCR
Handgeschreven tekstherkenning vs. Optical Character Recognition
HTR en OCR zijn verwante technologieën maar pakken fundamenteel verschillende uitdagingen aan. Het begrijpen van het verschil is belangrijk bij het evalueren van tools voor historische documentverwerking.
| Feature | HTR (Handgeschreven tekstherkenning) | Standaard OCR |
|---|---|---|
| Ontworpen voor | Handgeschreven en cursieve tekst | Gedrukte en getypte tekst |
| Tekensegmentatie | Niet nodig — verwerkt verbonden streken als sequenties | Vereist het isoleren van individuele tekens |
| Historische schriften | Kurrent, Secretary Hand, Copperplate en 100+ meer | Beperkte of geen ondersteuning |
| Trainingsaanpak | Deep learning op gelabelde handschriftvoorbeelden (ground truth) | Regelgebaseerde patroonherkenning of op drukwerk getrainde modellen |
| Aanpasbaarheid | Op maat gemaakte modellen kunnen worden getraind voor specifieke handschriften of schriften | Over het algemeen vast — kan zich niet aanpassen aan nieuwe handschriftstijlen |
| Nauwkeurigheid op handschrift | Doorgaans 90-98% tekennauwkeurigheid met getrainde modellen | Vaak onder 50% op cursief of historisch handschrift |
| Lay-outanalyse | Verwerkt complexe lay-outs: kolommen, tabellen, marginalia | Basaal — gaat uit van eenvoudige links-naar-rechts tekstflow |
| Verbonden schriften | Ja — Arabisch, Hebreeuws, cursieve Latijnse schriften | Beperkt of niet ondersteund |
| Aangetaste documenten | Robuust — getraind op echte historische documenten met schade | Prestatie daalt aanzienlijk |
| Betrouwbaarheidsscores | Betrouwbaarheidsscores per teken en per regel | Varieert — vaak afwezig of onbetrouwbaar |
Vergelijking weerspiegelt de algemene mogelijkheden van HTR-systemen (waaronder Transkribus) versus standaard OCR-engines. Specifieke resultaten hangen af van documenttype, modelselectie en documentconditie.
Dekking
Welke schriften, talen en eeuwen ondersteunt HTR?
Moderne HTR-platforms — Transkribus in het bijzonder — ondersteunen een opmerkelijk breed scala aan schriften, talen en historische perioden. De sleutel is de beschikbaarheid van getrainde modellen. Omdat HTR-modellen leren van voorbeelden in plaats van regels, kan elk schrift waarvoor voldoende trainingsdata bestaat worden ondersteund. Transkribus biedt meer dan 300 publieke modellen bijgedragen door onderzoekers en instellingen wereldwijd, die documenten dekken van de 9e eeuw tot heden.
Latijnse schriften: moderne en historische varianten waaronder Kurrent, Sütterlin, Secretary Hand, Copperplate, Humanistisch en gotisch cursief
Niet-Latijnse schriften: Arabisch, Hebreeuws, Grieks, Cyrillisch, Devanagari, Chinees, Japans en meer — met beschikbare of trainbare modellen
100+ talen vertegenwoordigd in de publieke modelcatalogus, van Duits en Engels tot Fins, Hongaars en Osmaans-Turks
Tijdspanne van middeleeuwse manuscripten (9e eeuw) via vroegmoderne administratieve registers tot 20e-eeuwse correspondentie
Documenten met meerdere schriften: modellen kunnen pagina's verwerken die meerdere schriften bevatten (bijv. Latijnse koppen met Kurrent-lopende tekst)










Wie gebruikt HTR
Handgeschreven tekstherkenningstechnologie in de praktijk
HTR is voorbij het experimentele stadium. Het is nu een productietool die wordt gebruikt in de geesteswetenschappen, het cultureel erfgoed en de informatiewetenschap. Onderzoekers gebruiken het om doorzoekbare corpora op te bouwen uit manuscriptcollecties. Archieven gebruiken het om achterstanden van ongedigitaliseerde bestanden te verwerken. Bibliotheken gebruiken het om bijzondere collecties vindbaar te maken. De technologie is bijzonder transformatief in contexten waar het volume handgeschreven materiaal handmatige transcriptie economisch onmogelijk maakt.
Digital humanities-onderzoekers die correspondentie, dagboeken en literaire manuscripten transcriberen voor wetenschappelijke edities
Nationale en gemeentelijke archieven die administratieve registers, gerechtelijke stukken en burgerlijke registers op schaal verwerken
Bibliotheken en bijzondere collecties die toegangen en catalogusrecords doorzoekbaar en vindbaar maken
Genealogen die kerkregisters, volkstellingsregisters en burgerlijke akten in historische schriften lezen
Cultureel-erfgoedprojecten die bedreigde manuscriptcollecties digitaliseren vóór fysieke achteruitgang

Verder dan herkenning
De volledige pipeline: van handgeschreven document naar gestructureerde data
Handgeschreven tekstherkenning is één stap in een grotere documentverwerkingspipeline. Een volledige workflow begint met digitalisering (scannen of fotograferen), gaat verder met lay-outanalyse en tekstherkenning, en vervolgt met naverwerking: entiteitsherkenning, metadata-extractie, gestructureerde export en publicatie. Transkribus integreert al deze stadia in één platform, zodat onderzoekers niet afzonderlijke tools hoeven samen te voegen voor elke stap.
Lay-outanalyse: automatische detectie van tekstgebieden, kolommen, tabellen, koppen en marginalia
Tekstherkenning: HTR converteert gedetecteerde tekstregels naar machineleesbare tekens
Training van op maat gemaakte modellen: verfijn modellen op je specifieke manuscripttype voor hogere nauwkeurigheid
Entiteitsherkenning en tagging: identificeer personen, plaatsen, datums en andere benoemde entiteiten in de getranscribeerde tekst
Exporteer als TEI-XML, PAGE XML, ALTO XML, doorzoekbare PDF of platte tekst — klaar voor analyse, publicatie of archiefingest

Veelgestelde vragen over handgeschreven tekstherkenning
OCR (Optical Character Recognition) is ontworpen voor gedrukte tekst en werkt door individuele tekenvormem te matchen met bekende lettertypen. HTR (Handwritten Text Recognition) gebruikt deep learning om verbonden, variabel handschrift te verwerken als reeksen pennenstreken in plaats van losse tekens. HTR kan cursieve schriften, historische handen en de natuurlijke variatie in handschrift verwerken — taken waar standaard OCR doorgaans faalt. Kort gezegd: OCR leest drukwerk, HTR leest handschrift.
HTR-modellen worden getraind op gekoppelde datasets die 'ground truth' heten: afbeeldingen van handgeschreven tekst gekoppeld aan de correcte transcripties. Het neurale netwerk leert visuele patronen in het handschrift te koppelen aan tekenreeksen. Training vereist doorgaans 50-100 getranscribeerde pagina's voor een eigen model, hoewel grotere datasets de nauwkeurigheid verbeteren. Het model leert niet alleen lettervormem maar ook contextuele patronen — hoe tekens verbonden zijn, veelvoorkomende afkortingen en schriftspecifieke conventies.
Nauwkeurigheid wordt gemeten met de Character Error Rate (CER) — het percentage tekens dat verschilt tussen de HTR-output en de correcte tekst. Goed getrainde modellen op leesbare schriften bereiken routinematig CER onder de 5% (meer dan 95% tekennauwkeurigheid). Lastige documenten — zwaar beschadigd, vervaagd of in ongebruikelijke schriften — kunnen een CER van 10-15% opleveren voor aangepaste training. Na het finetunen van een model op uw specifieke documenttype verbetert de nauwkeurigheid doorgaans aanzienlijk.
HTR werkt op vrijwel elk handgeschreven document waarvoor een getraind model bestaat of gemaakt kan worden: brieven, dagboeken, DTB-registers, rechtbankdossiers, administratieve archieven, bevolkingsregisters, wetenschappelijke notitieboeken, literaire manuscripten, notariele akten en meer. Het verwerkt ook gemengde documenten met zowel drukwerk als handschrift. De belangrijkste voorwaarde is een model dat getraind is op een vergelijkbaar schrift en documenttype.
Transkribus, het toonaangevende HTR-platform, biedt 50 gratis credits per maand — genoeg om ongeveer 50 pagina's te verwerken. Geen creditcard nodig om te beginnen. Betaalde plannen zijn beschikbaar voor onderzoekers en instellingen die grotere volumes verwerken. Bekijk plannen en prijzen voor details.
Een enkele pagina duurt doorgaans 15-30 seconden om te verwerken, afhankelijk van de documentcomplexiteit en het gebruikte model. Batchverwerking maakt het mogelijk om honderden of duizenden pagina's in de wachtrij te plaatsen en automatisch te verwerken. Een manuscript van 500 pagina's kan in minder dan een uur worden getranscribeerd — werk dat met de hand weken of maanden zou kosten.
Transkribus biedt meer dan 300 publieke HTR-modellen voor 100+ talen en schriften. Dit omvat Latijns-schrift talen (Engels, Duits, Frans, Spaans, Nederlands, Zweeds en vele andere), evenals Arabisch, Hebreeuws, Grieks, Cyrillisch en andere schriftsystemen. Historische schriften zoals Kurrent, Sutterlin, Oud-Schrift en Copperplate zijn goed vertegenwoordigd. Als er geen model voor uw specifieke schrift bestaat, kunt u een eigen model trainen.
Zie HTR in actie
Ontdek handleidingen per gebruiksscenario
Zie hoe HTR wordt toegepast op echte documenten: Kerkregisters · Volkstellingsregisters · Middeleeuwse manuscripten · Archiefachterstand verminderen · Maak doorzoekbare PDF's

Klaar om handgeschreven tekstherkenning te proberen?
Maak een gratis account aan en verwerk je eerste documenten met Transkribus. 50 gratis credits per maand — geen creditcard nodig.
Gebruikt door 500+ universiteiten en onderzoeksinstellingen
200 M+Pagina's verwerkt
500.000+Gebruikers wereldwijd
300+Publieke HTR-modellen