Russian generic handwriting 2
Description
Try this model
Drag an image here
Select a file...PNG or JPG up to 10 Mb
By uploading an image, you accept our terms and privacy policy.
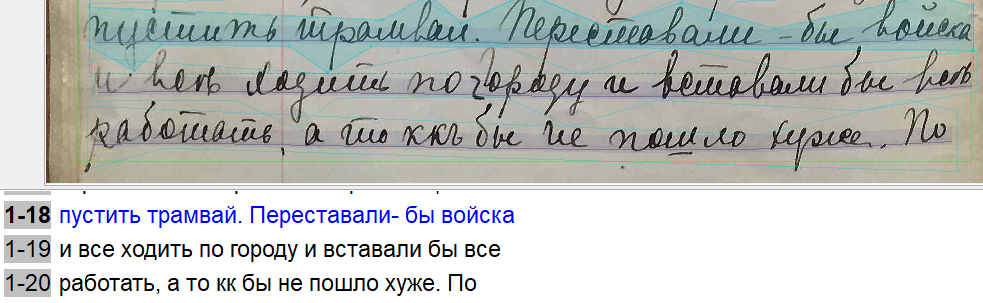
Character Error Rate (CER) measures the percentage of characters incorrectly recognised. Lower is better. This model scored 5.8% on its validation set. As a rule of thumb, a CER below 10% is considered good for most handwritten material. This is a larger model trained on diverse material, which generally makes it more robust across different handwriting styles. That said, larger training sets also make it harder to push the CER down further.
Measured on the model's own validation data. Results on your documents may differ depending on handwriting style, document condition, language, and how closely your material resembles the training data.